Inference for a Single Proportion
STAT 218 - Week 7, Lecture 1
February 20th, 2024
Motivating Example
Dogs have a keen sense of smell. They are used for search and rescue, explosive detection, sniffing out illegal drugs in luggage at airports, and locating game while hunting.
- Can they also tell whether someone has COVID-19 by sniffing a specimen of sweat from a person?
We will be looking at a study that used several dogs to test this question.
- We will focus on one dog, Maika, a 3-year-old female Belgian Malinois whose specialty is search and rescue.
- Maika completed 57 trials where she would sniff four different sweat specimens, one of which was from a COVID positive person, and then sit in front of the specimen she determined to be the positive specimen.

- The researchers found that in 47 of the 57 trials Maika chose the COVID positive specimen.
Let’s identify the observational unit, type of variable, statistic, sample, parameter, and population.
Motivating Example
- Let’s produce a bar graph representing the observed results.
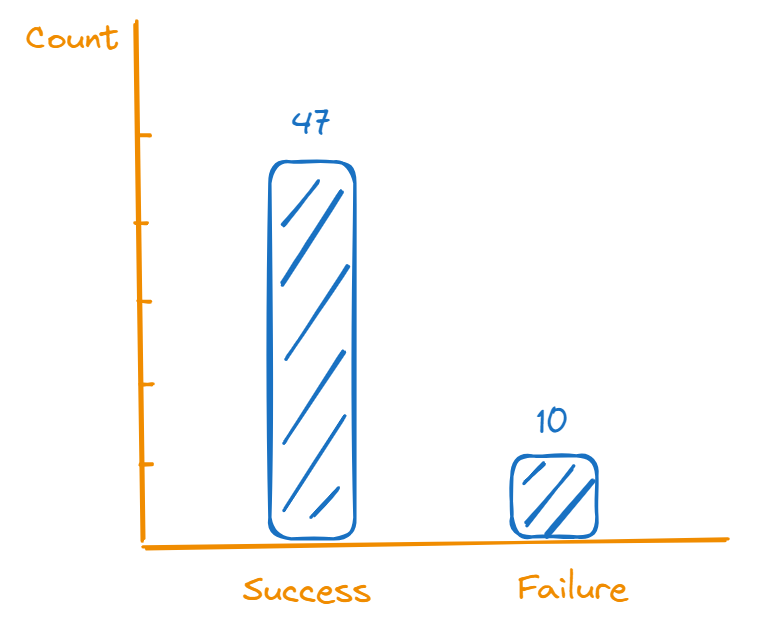
- Do these results convince you that dogs can detect COVID-19?
- How many would Maika need to get correct to convince you?
- Does it need to be all 57?
- If Maika does not have some ability to identify the COVID specimen from the sweat of a person, what is another explanation for her getting so many correct?
- Research Question?
- Does Maika tend to correctly identify the COVID specimen?
One Proportion Using A Spinner
- Let’s use our applet to generate “null distribution”.

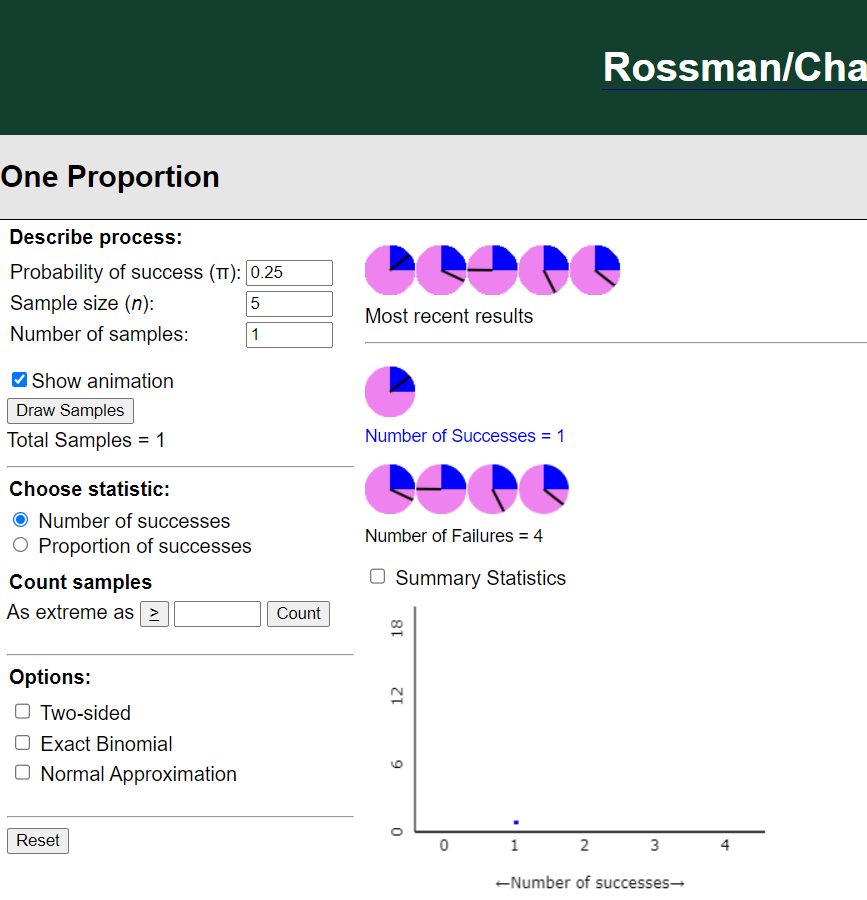
Formulate Conclusions
- Based on these simulation results, would you consider it surprising for Maika to correctly identify the COVID specimen 47 times?
- Let’s reconsider those two competing explanations. Which one appears more plausible to you?
- In the long-run, Maika has a genuine tendency to correctly identify the COVID specimen
- In the long run, Maika does not have a genuine tendency and is simply guessing among the specimens each time (she got lucky)
- In this case, the observed statistic is far out in the tail of the distribution and it is not hard to see that Maika’s proportion of successful identifications is unlikely to happen by random chance.