One Sample \(t\)-tests & Comparison of Paired Samples
STAT 218 - Week 6, Lecture 1
February 12th, 2024
A Hypothesis Testing Example From Physics
In 2012, physicists suggested that they had discovered the existence of a subatomic particle known as the Higgs boson, based on some data and a \(P\)-value of 0.0000003. What they meant was:
- If the particle does not exist (the null hypothesis), then the probability of their data (or more extreme) was 0.0000003. That is a lot less than the arbitrary 0.05 and is pretty convincing.

Example 8.1.1
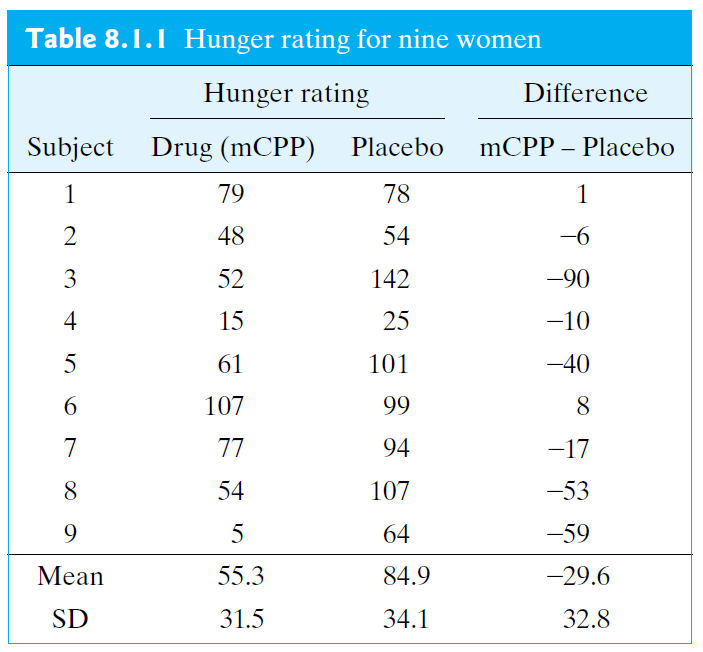
Hunger Rating During a weight loss study, each of nine subjects was given (1) the active drug m-chlorophenylpiperazine (mCPP) for 2 weeks and then a placebo for another 2 weeks, or (2) the placebo for the first 2 weeks and then mCPP for the second 2 weeks. As part of the study, the subjects were asked to rate how hungry there were at the end of each 2-week period.
Let us test \(H_0\) against \(H_A\) at significance level \(\alpha\) = 0.05.
\(H_0: \mu_{D} = 0\) \(H_A: \mu_{D} \neq 0\)
An Introduction to Decision Errors
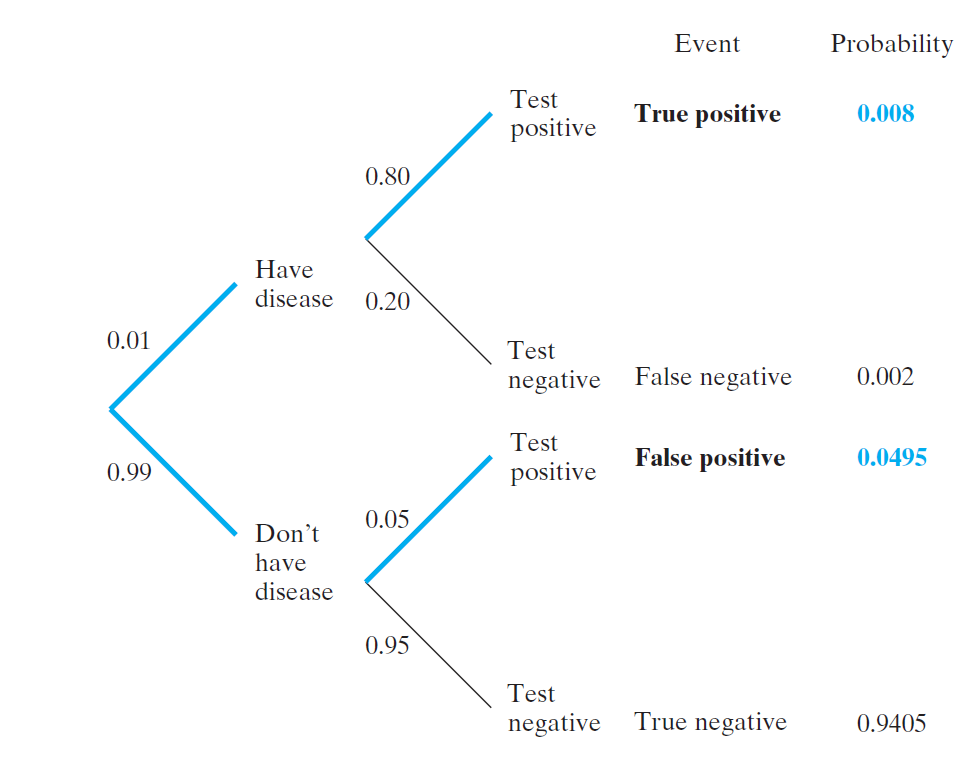
Type II Error (\(\beta\))
Definition
\(\beta\) = Pr{lack of significant evidence for \(H_A\)} if \(H_A\) is true
OR
failing to reject the null hypothesis when the alternative is actually true.
- If \(H_A\) is true, but we do not observe sufficient evidence to support \(H_A\), then we have made a Type II error.
- Table 7.3.2 displays the situations in which Type I and Type II errors can occur.
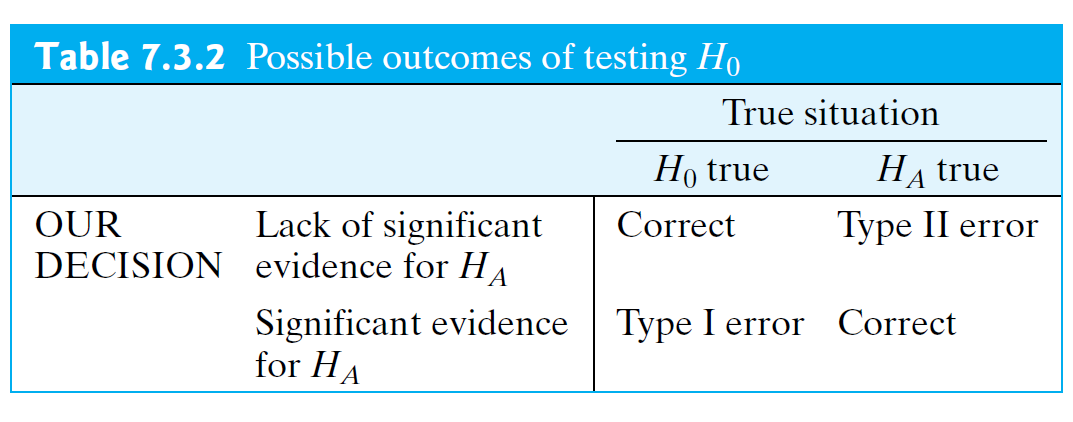
- For example, if we find significant evidence for \(H_A\), then we eliminate the possibility of a Type II error, but by rejecting \(H_0\) we may have made a Type I error.
Type I Error vs Type II Error

From Essential Guide to Effect Sizes by Paul D. Ellis (2010)