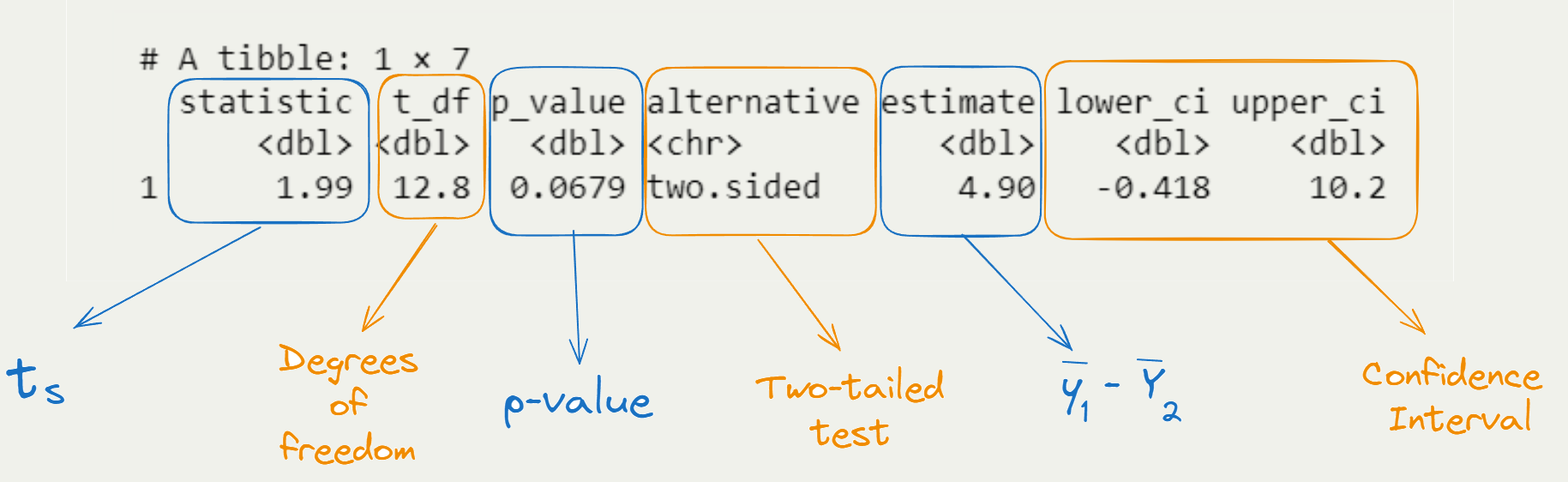
# A tibble: 1 × 7
statistic t_df p_value alternative estimate lower_ci upper_ci
<dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
1 1.99 12.8 0.0679 two.sided 4.90 -0.418 10.2Introduction to Hypothesis Testing & Comparison of Independent Samples
STAT 218 - Week 5, Lecture 4
February 8th, 2024
Step 3. Calculate test statistic and find the P-value (cont.d)

Step 4. Draw Conclusion (cont.d)
Important
We can think of a as a preset threshold of statistical significance (OR the risk of false positive finding).
- If the P-value of the data is less than or equal to \(\alpha\),
- the data are judged to provide statistically significant (some like to express this as ‘statistically discernible’) evidence in favor of \(H_A\); we also may say that \(H_0\) is rejected.
- If the P-value of the data is greater than \(\alpha\),
- we can say that the data provide insufficient evidence against the \(H_0\), and thus we fail to reject \(H_0\).

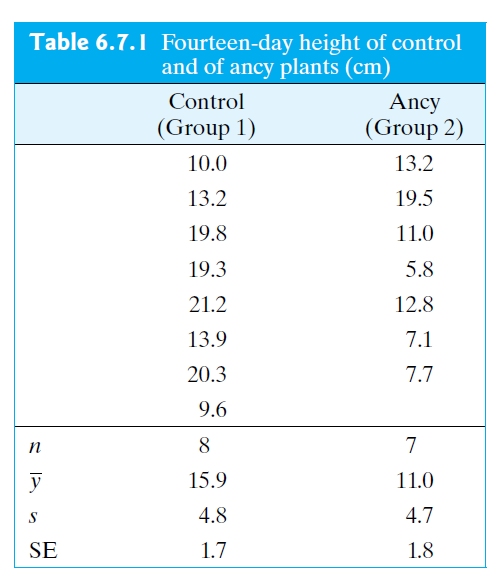
The Same Example for (\(\mu_1\) - \(\mu_2\))
The Wisconsin Fast Plant, Brassica campestris, has a very rapid growth cycle that makes it particularly well suited for the study of factors that affect plant growth.
In one such study, 7 plants were treated with the substance Ancymidol (ancy) and were compared to 8 control plants that were given ordinary water. Heights of all of the plants were measured, in cm, after 14 days of growth.
(\(df\) for this question is calculated as 12).
Let’s see an example for hypothesis testing by using \(\alpha = 0.05\)
Interpretation of R Output