Descriptive Statistics in R
STAT 218 - Week 3, Lecture 3, Lab 2
January 24th, 2024
Today’s Menu
Today we will be familiar with
- Data Frames
- Loading Data into R
- Summary Statistics
ggplot()
Last Week’s Favourites - 1
No boundaries
Last Week’s Favourites - 2
Quarto Loves Secure Attachment
How to Build A Healthy Relationship with Quarto
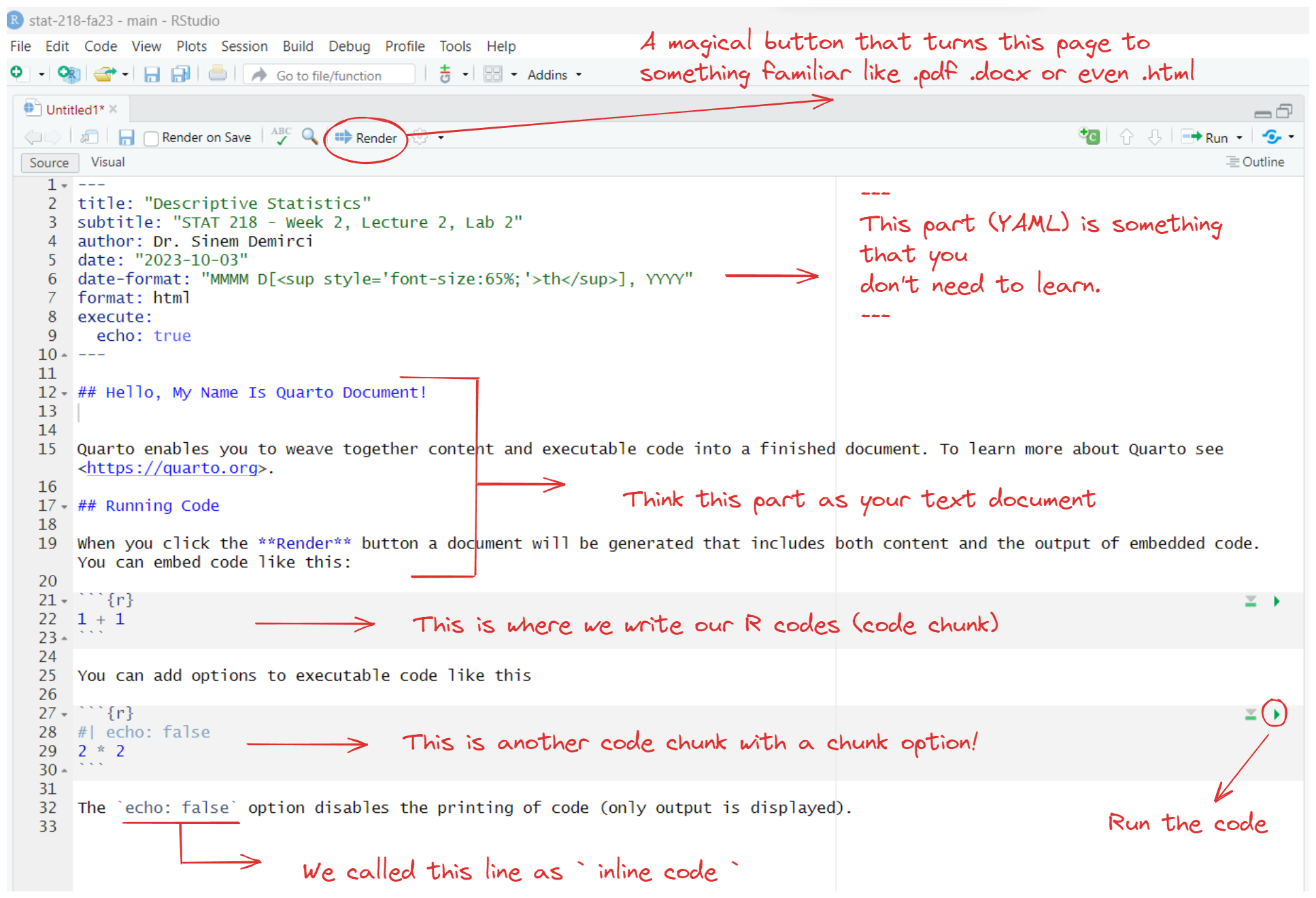
Quarto Document Parts
Before Proceeding Further…
Before Proceeding Further…
Creating This Week’s Quarto Document
Tip
- Let’s create this week’s Quarto document by clicking
File > New File > Quarto Document - Give a title as “Week 3 Lab 3 Descriptive Statistics”
- Add your own notes and the given codes to this document
- DO NOT FORGET to save it to your STAT 218 Folder!
Library Function in R
The library() function in R is like opening a toolbox. Imagine you have a toolbox filled with different tools, and each tool helps you do a specific job. Similarly, in R, a library is like a toolbox that contains specialized tools (packages) for specific tasks.
When you use the library() function, you’re telling R to open a specific toolbox (load a package) so that you can access and use the tools inside.
Let’s add a code chunk to our Quarto document and type the code below.
How to Load Data into R
We have two different ways to do that (within the scope of this class)
- Using an available dataset stored in R (packages)
- Importing a dataset from an outside source
Import Dataset from An Outside Source
Getting to Know Your Data
After importing our data, it is important to familiarize with our data. We have some functions to do that.
Let’s start with glimpse() function. The name of this function is self-explanatory.
glimpse() function gives us a brief information about out data set. We have 6 variables and 180 cases or observations.
Getting to Know Your Data
Alternatively, we can ask R the number of columns (variables) and rows (cases) as following:
[1] 6[1] 180Assume that I would like to see just the names of the variables in my data set. I can use name()function for this.
Frequency Distribution Table (An Ugly One!)
Measures of Central Tendency
We can calculate measures of central tendency by using these unsurprising functions.
Measures of Central Tendency
Alternatively, you can use summarize() function for the same calculation.
Measures of Dispersion
Alternatively, you can use summarize() function.
Or…
An Example for Bar Chart
Let’s plot a simple bar chart. Next session, we will explore other features for ggplot().