Chapter 2: Description of Samples and Populations
STAT 218 - Week 2, Lecture 3
January 18th, 2024
More on Histograms
A histogram is like a visual story in two parts.
- Look at the tops of the bars to understand the distribution’s shape.
- The area within each bar tells us two things:
- It is proportional to the corresponding frequency.
- It represents the number of observations in that category.
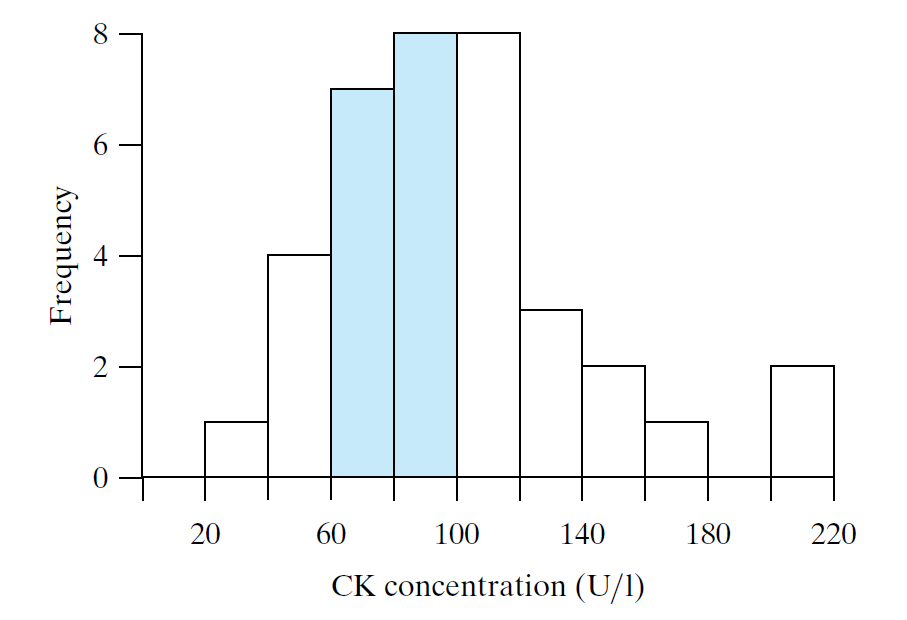
Let’s elaborate yesterday’s example
- The shaded area is 42% of the total area in all the bars.
- 42% of the CK values fall into the corresponding classes
- 15 out of 36 values lie between 60 U/I and 100 U/l.
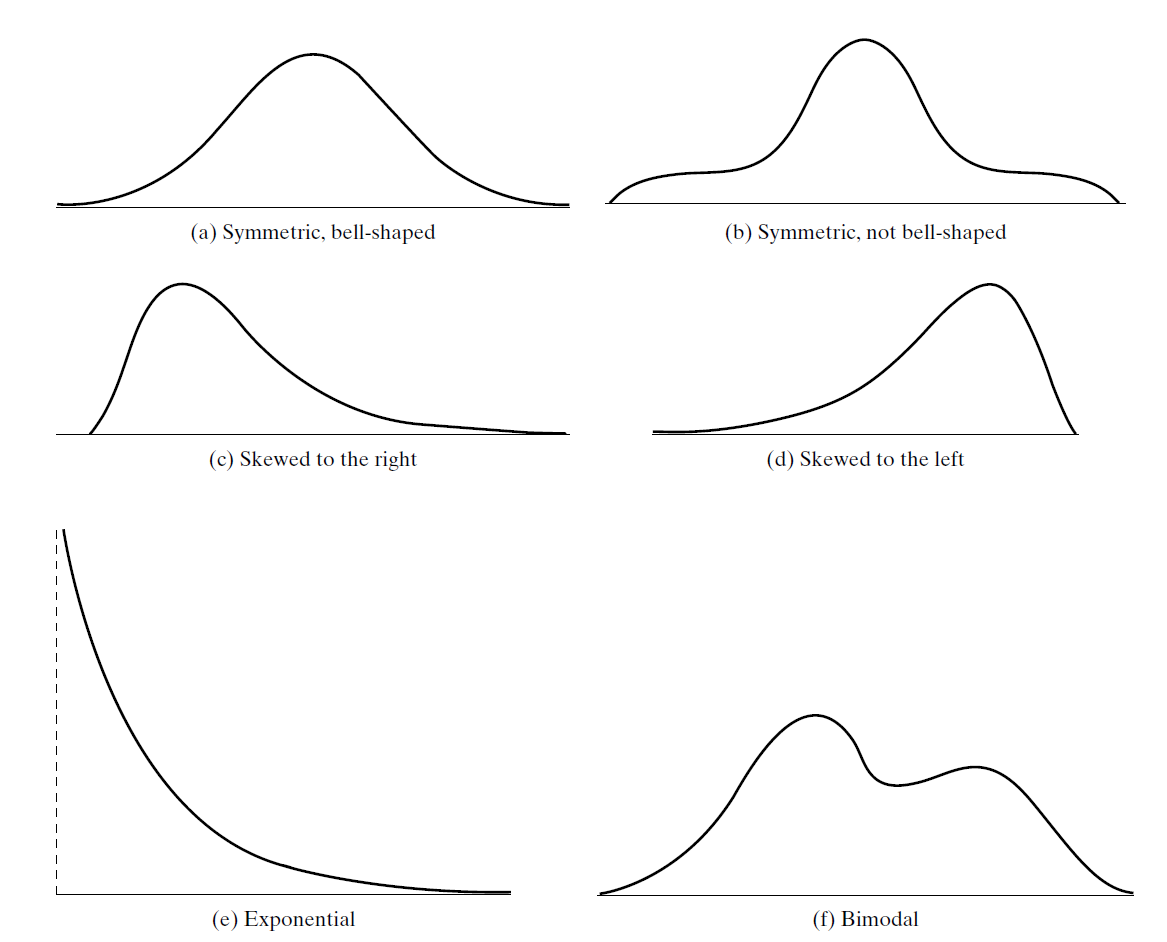
Shapes of Distributions
Mean
We calculate the mean by using this formula

Standard Deviation and Variance

- Variance is denoted as \(s^2\), which is the standard deviation squared
- Let’s calculate standard deviation for each squirrel group!
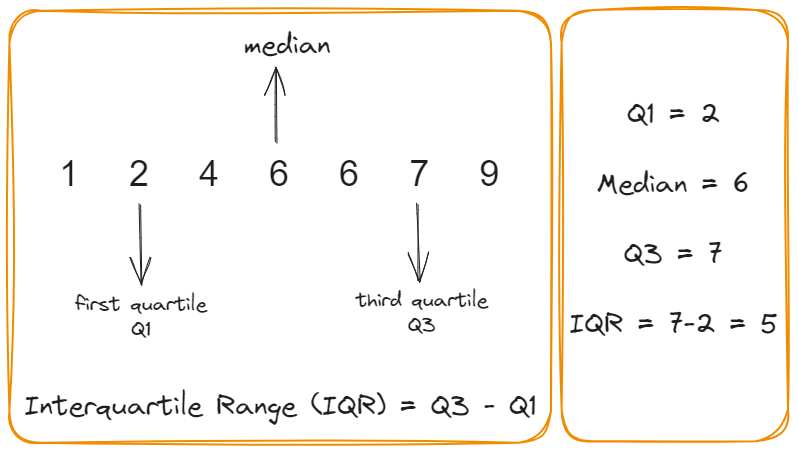
Quartile Range & Interquartile Range